
Background.
At Via, our Platform team is committed to building and standardizing tools and infrastructure that empower developers to efficiently deliver resilient, scalable, and production-ready solutions.
Our mission is to drive innovation by creating self-service tools that offer a consistent, secure, and standardized experience while enabling developers to work quickly and independently, supporting Via’s rapid growth.
Support bottlenecks.
Some of the main challenges in achieving this goal are the support overhead for tools we provide to the engineering teams as well as handling day-to-day questions regarding our cloud infrastructure.
Historically, when developers faced an infra-related problem, they would either open a support ticket to the team or ask their questions in a dedicated Slack channel. In either case, the developer would often be blocked in their work until they received a response from a Platform engineer, who’d need to identify and resolve their issue.
Take this example:

Typically for such a query, a Platform engineer would need to notice the question in the channel and potentially allocate time in their sprint to investigating the issue, locating relevant documentation, or referencing similar past cases.
Relying on engineers to address day-to-day, often repeating issues presented an opportunity to streamline operations within the Platform team while empowering developers to work more efficiently - unlocking more independence and greater development velocity.
AI to the rescue.
With the rise of AI, we found an elegant solution to this challenge, drastically reducing the support bottleneck for our Platform team, and allowing developers to work more efficiently.
High-quality documentation for every project and tool developed has always been a priority at Via. However, this excellent knowledge base was being underutilized as a means of resolving recurring issues. Instead of relying on a Platform engineer to answer questions manually, we are now leveraging our official documentation as a means of automating responses through an AI-powered chatbot. This approach ensures developers get instant, accurate answers while freeing up the Platform team to focus on innovation.
The same question mentioned previously would be answered automatically, without requiring intervention from the platform engineers:

How does it work?
Our solution operates through two straightforward workflows.
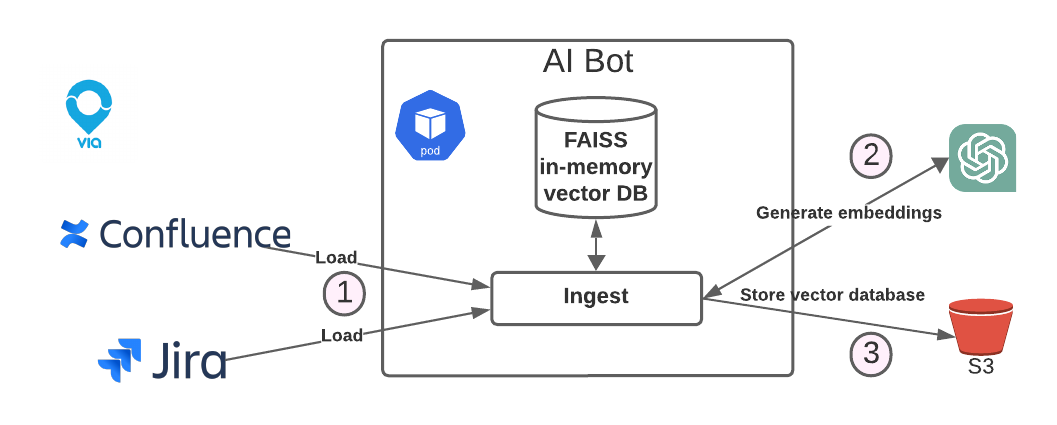
1. The ingestion pipeline flow
We use Atlassian Confluence for our internal documentation. To include a document in the bot’s knowledge base, team members simply add a “GPT-include” label to their Confluence page.
Once a day, the ingestion pipeline is triggered, fetching all the labeled documents via the Confluence API while generating embeddings for their content. These embeddings are then stored and indexed, enabling the bot to provide accurate and context-aware responses.
Embeddings are numerical representations of text, mapped into a high-dimensional space where semantically similar items are positioned closer together. This allows for efficient similarity searches by comparing the proximity of embeddings to identify related content—a concept we’ll explore further in the next flow.
To generate these embeddings, we leverage the OpenAI API, ensuring accurate and high-quality semantic representation of our documentation. Once the embeddings are generated, we store the text of all documents, along with their metadata and embeddings, in a vector database.
A vector database is a specialized system designed for storing and querying high-dimensional vectors, such as embeddings. It excels at tasks like similarity searches, using operations like nearest-neighbor search to quickly identify vectors that are closest to a given query. This makes it an essential component for enabling fast and accurate AI-driven responses.
There are many different vector databases available, each suits several use cases. Since our initial dataset was relatively small (a few thousand documents), we chose to use FAISS - an open-source, in-memory vector database developed by Meta.
After building the vector database, we export it to a file and upload it to an S3 bucket. This ensures the data is readily accessible for the next pipeline in our workflow.
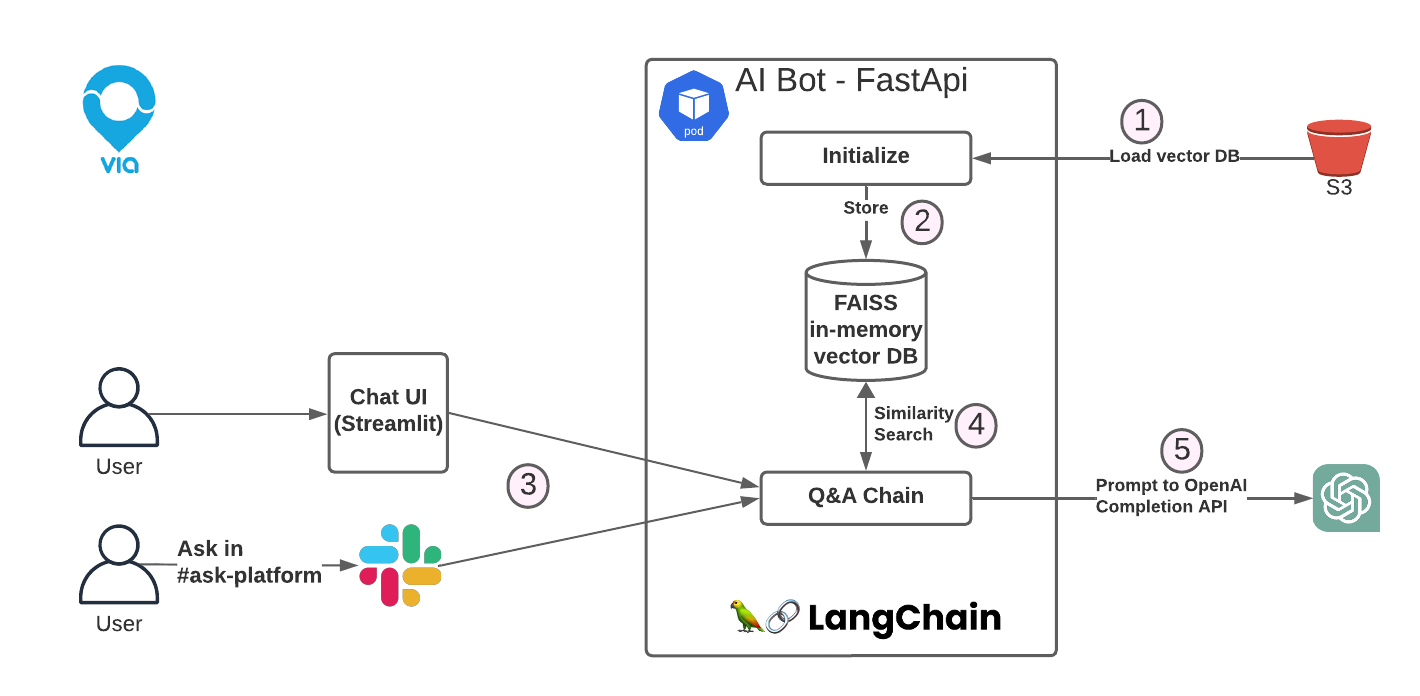
2. The question-answering flow
Our bot is built as a FastAPI app, deployed to an EKS cluster, that retrieves the S3 file and loads it into the in-memory FAISS vector database.
When a user asks a question in our dedicated Slack channel, Slack triggers a webhook, which eventually hits an endpoint in our FastAPI app.
This endpoint is responsible for performing a similarity search to identify documents with text similar to the user’s question. This process involves converting the question into embeddings and querying the vector database to find document embeddings that are closest in proximity to the question’s embedding.
Thanks to vector databases, this process is straightforward. In our case, it’s as simple as:
docs_and_scores = db.similarity_search_with_score(question)
From the results, we select the top documents with the highest matching scores that exceed our predefined threshold. These selected documents are then used as input for a call to a large language model (LLM) via the OpenAI API.
The prompt sent to the LLM consists of the user’s question as well as the text of the selected documents from the similarity search.
Remarkably, the response not only answers the question but often provides additional details, such as example code, YAML configurations, and other relevant information, enriching the developer’s experience and solving their queries comprehensively. Now, issues that might’ve taken hours or days to be attended to by a Platform engineer are resolved nearly instantly and in a much more thorough manner.
How do we handle interactions with the LLM and a vector database?
To seamlessly integrate the various components of our system, we leverage the LangChain framework. LangChain facilitates interactions with LLMs and provides a unified interface for supported tools, making it easy to swap out components like LLMs or vector databases with minimal effort.
LangChain allows us to construct chains that utilize AI for solving complex problems. In our use case, we rely on a ConversationalRetrievalChain. This chain combines a vector database containing text and embeddings with a conversational interface, enabling the LLM to provide contextually rich answers while continuously incorporating relevant text retrieved from the database.
The core of this workflow can be summarized in the following code:
db = FAISS.load_local(consts.FAISS_DB_DIR_PATH, OpenAIEmbedding())
chat = ChatOpenAI(temperature=0, model_name="gpt-4o")
retriever = db.as_retriever()
chain = ConversationalRetrievalChain.from_llm(llm=chat, retriever=retriever)
result = chain({"question": question, "chat_history": chat_history})
This setup enables smooth interaction between the user, the vector database, and the LLM, delivering accurate and dynamic responses to queries.
Sound familiar?
Numerous SaaS products and startups are offering “one-click” solutions for this kind of integration. Our approach at Via is to solve problems efficiently by carefully selecting the right approach - whether using open-source tools, commercial solutions, or developing our solution from scratch. We consider factors such as functionality, cost-effectiveness, ease of integration, engineering effort required, and affordability.
Bot on steroids.
Our AI bot has been operational for over a year, and after a short fine-tuning period, it now provides accurate and concise answers. During this process, we also refined and cleaned up our documentation to improve response quality.
Although it started as an initiative to assist Platform Engineering, the bot has quickly expanded its reach. It is now used by a variety of teams across Via—including product managers and developers across different groups—to provide faster answers and minimize the time wasted on Q&A, significantly improving efficiency and productivity company-wide.
Example of a Product Question:

Moving forward: expanding the bot’s capabilities.
The LangChain framework has enabled us to design or implement several innovative features, including:
-
Automatic code reviews: Reviewing pull requests based on code standards documentation.
-
Database query integration: Answering questions using our settings database as the source.
-
Risk analysis automation: Automatically analyzing production change risks and adding insights to Jira tickets.
The day when AI can truly handle end-to-end flows - both answering questions and executing relevant operations - may be closer than we think.
Be part of our next wave of innovation.
And this was just the beginning! We have a growing list of ideas to further enhance developer efficiency at Via. We’re always on the lookout for talented engineers who are eager to bring these ideas to life or propose new ones. If you find this exciting, reach out — we may end-up building the future together!



.png?width=71&height=47&name=Sioux%20Falls%20Webinar%20(6).png)
