
The road to self-service.
Via is a fast-growing company. In its early years, as teams scaled quickly, each had full autonomy to build their own code, infrastructure, CI/CD pipelines, and observability solutions. This autonomy fueled rapid innovation — enabling us to support hundreds of partners within just a few years.
The limits of full autonomy.

Over time, the lack of centralization revealed its limits.
As each team used a different source code management system (GitLab and GitHub) and a different CI/CD (GitHub Actions, GitLab CI/CD, Jenkins, CircleCI, and more), we reached a point where driving cross-company projects in these areas became increasingly complex.

For example, creating a new stage for checking security issues in a pull request or measuring code coverage, required allocating a large amount of resources for each and every team and asking them to implement it on their own SCM and CI/CD.
Such projects could last many weeks, as dev teams were primarily focused on building the product. Moreover, not all teams had deep expertise in these domains, leading to solutions that were effective locally but varied in structure and tooling across the company.
Building the foundation for platform engineering.
In 2021, we founded the Platform Engineering team. Our mission was to build the next evolution of tools designed to help over 50 teams advance, consolidate, and expedite their workflows.
The first thing we tackled in the early days was setting a single standard for source code management and CI/CD. This was the largest pain point at the time, given the diverse tooling landscape across teams and the increasing need for unified cross-R&D changes in the software development lifecycle. We chose GitLab CI/CD, as it was already adopted by a significant portion of the teams and offered all the features we needed to build a robust and extensible CI/CD pipeline.
We created a hierarchical structure using GitLab groups, created CI/CD templates, and then drove a large project that involved all R&D, where we helped teams migrate their SCM and CI/CD to the new standard.
This is what we set out to achieve:

By the end of this initiative, all teams aligned on a single source code and CI/CD standard, significantly reducing complexity and unlocking our ability to drive cross-cutting improvements at scale.
Here’s what the .gitlab-ci.yml file looks like in all repositories—it simply references a shared CI/CD template that generates the pipeline:

With the CI/CD foundation in place, we turned our attention to the next major bottleneck: infrastructure provisioning.
Standardizing cloud infrastructure provisioning.
Tackling the next challenge: infrastructure provisioning.
Even after aligning CI/CD processes across all teams, there was still inconsistency in how infrastructure was provisioned in our AWS environment.
Some teams used CloudFormation directly, others relied on the Serverless Framework (which generates CloudFormation under the hood), some used Terraform, and others used ClickOps — manually creating resources through the AWS console.
Even among teams that chose a single Infrastructure as Code (IaC) framework like Terraform, many projects used a direct approach rather than shared modules, which worked initially but became harder to maintain at scale. Instead, they often defined infrastructure resources repeatedly across different projects using raw Terraform resources without leveraging reusable modules. This caused duplication, inconsistent configurations, and increased the likelihood of human error.
Example of a Cloudformation definition of some DB. This is just part of the configuration:

Our goal was clear: to standardize not only the choice of IaC framework but also how it’s used — promoting consistency and reuse through shared, modular templates.
The RDS example: repetition and inconsistency at scale.
Let’s take AWS RDS database provisioning as an example.
A team might own dozens of services and multiple databases. Since we operate across 6 AWS regions, each database must be provisioned with identical configurations in all regions. This means a single team could be managing up to 50 separate database clusters.
At the time, these configurations were often inconsistent across regions, mainly because not all teams followed the DRY principle (Don’t Repeat Yourself). Additionally, each team made independent decisions regarding key aspects such as backup policies, security settings, and alerting configurations.
Some of these were complex to implement correctly, and not every developer was familiar with the finer details of compliance, security, resilience, and availability standards. This made it harder for teams to anticipate and align with emerging compliance and availability standards as the organization scaled.
For example, setting up a single memory alert—which is just one step of many for properly provisioning a production RDS database — involves multiple coordinated steps: defining the CloudWatch metric, creating or reusing an SNS topic, configuring the right publish permissions, subscribing notification endpoints, securely storing the PagerDuty webhook, and connecting it to the SNS topic.
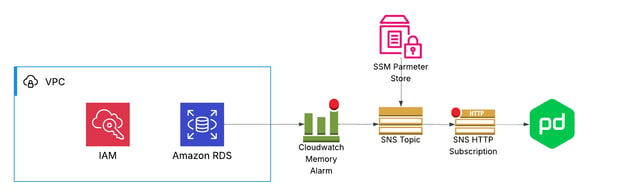
Our solution: abstracting weeks of infrastructure knowledge into 6 reusable lines of code.
We started by addressing cloud infrastructure provisioning. Our goal was clear: empower teams to use Infrastructure as Code (IaC) aligned with company-wide standards — ensuring security, compliance, and operational best practices — while abstracting the complexity so developers could stay focused on building their products.
We built a suite of Terraform modules covering AWS services like RDS, ElastiCache, SNS, SQS, S3, EKS, IAM, CloudWatch alarms, and more - all with the correct defaults pre-configured.
Spinning up a new database now automatically applied Via’s standards.
Developers interact with it through a simple, intuitive snippet — packing infrastructure expertise into just a few reusable lines of code.:

Behind the scenes: what the RDS module provides.
Behind the scenes, the rds Terraform module provisions a set of resources that together form a complete, standards-compliant RDS cluster from 48 resources and 4 modules, including:
- Network configuration (subnets, security groups, etc.)
- Audit logs sent to security accounts
- IAM roles with rotating MySQL secrets
- Backup policies that meet compliance standards
- CloudWatch alarms integrated with PagerDuty
- Auto-scaling configurations
This suite of modules, and the ease of using them, forms a core part of our self-service platform.
Abstracting complexity, enabling ownership.
Developers no longer need to manage complex configurations — we abstracted that for them.
They provide only minimal input, and they can override defaults if needed.
In the example below, additional parameter groups are layered on top of the defaults, and auto scaling settings are overridden using region-specific variables-since some regions are smaller and require different scaling configurations:

Everything is written in simple, standard Terraform HCL — developers just fill in a few variables, with no need to understand Terraform. At the same time, advanced users can leverage the full power of Terraform to customize or extend the setup as needed.
This approach achieves the right balance between simplicity, standardization, and flexibility — enabling teams to move faster without sacrificing governance or quality.
Adoption and outcomes: empowerment and acceleration.
Immediately seeing the benefit in this approach, developers began using self-service for new databases and started migrating existing ones to be managed through the self-service platform.
The ease of use empowered teams to take full ownership of provisioning their own infrastructure. They no longer had to wait for the Platform group to assist with changing or troubleshooting configurations.
Once most RDS databases at Via were provisioned through our self-service platform, we were able to introduce new capabilities that immediately benefited all teams — for example, alerts for slow or non-indexed queries, and automated database version upgrades using RDS blue-green deployment patterns with DMS replication, all integrated into our Terraform modules.
This initiative significantly boosted developer productivity and freed the Platform group to focus on new challenges instead of supporting infrastructure provisioning. When you factor in both the time saved by developers and the reduced support burden on the Platform team, the impact of this effort is hard to overstate — it fundamentally improved how efficiently, safely, and reliably teams could operate.
Deploying Kubernetes services.
Another area where we faced challenges in both developer productivity and consistency was deploying Kubernetes services.
The challenge.
There are several complexities involved in configuring and deploying a Kubernetes service, including:
- Maintaining a Kubernetes cluster over time
- Developing and maintaining Helm templates to provision manifests such as Deployments, StatefulSets, Services, Ingresses, Alerts, and Pod Disruption Budgets
- Creating and managing ECR repositories to store container images
- Configuring ArgoCD to sync manifests to the correct environment
- Setting up a CI/CD pipeline to build, test, and deploy the application to both Staging and Production environments across multiple regions in a consistent, reusable way, without duplicating configurations
The onboarding process for new services was so complex that dev teams frequently relied on the Platform group to handle it. However, because this process wasn’t automated, assembling all the necessary components required significant manual effort.
As a result, developers sometimes had to wait weeks or more depending on priorities and workload, or in some cases, opted for a different stack like Lambda, which worked well for some cases but didn’t always align with long-term architectural needs. Even with runbooks in place, natural variations emerged between implementations, leading to some inconsistencies in service configurations.
What we needed.
Solving this challenge meant tying together several infrastructure building blocks to create a seamless, consistent deployment experience. Here’s how deploying a single service from a single repository works today at Via with the self-service platform.
Building and pushing the image.
The first step is the CI/CD pipeline. It builds the Docker image from the repository’s Dockerfile and pushes it to the container registry (ECR). The Dockerfile itself comes from a predefined template used to generate the repository structure - more on that in the next blog post.
When the app is created, we automatically provision an IAM role and an ECR repository for it using our Terraform modules—just as we did for other resources earlier.

The generic Helm chart.
Next comes the deployment job.
We use a generic Helm chart to define all the Kubernetes components an application might need - such as Deployment, StatefulSet, CronJob, Service, Ingress, ConfigMap, HPA, Keda, AlertManagerConfig, ExternalSecrets, PDB, VPA, ServiceMonitor, and more.
This Helm chart is packaged, versioned, and published to GitLab’s Package Registry, making it easy for all services to consume. Developers simply reference the chart and provide a values.yaml file to override specific configurations.
This approach hides Kubernetes complexity from developers. All they need to focus on is the configuration options we expose. For power users, advanced customizations are still possible—striking the right balance between simplicity and flexibility.
Here’s what the Helm chart reference looks like:

And here’s an example of how it’s customized with values.yaml:

The deployment job then fetches the Helm chart, applies the values.yaml, and deploys it to the appropriate cluster using ArgoCD.
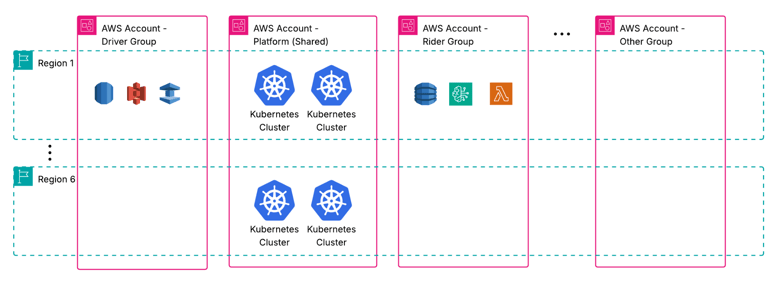
Centralized clusters and shared infrastructure.
We maintain multiple central Kubernetes clusters, deployed across various AWS accounts and regions, fully managed by the Production Engineering team within our Platform group.
This shared infrastructure allows dev teams to benefit from centralized optimizations, automated resource management, and reduced operational burden.
Self-service at scale.
Behind the scenes, our platform assembles numerous components: centrally governed Kubernetes clusters, reusable Terraform and Helm modules, CI/CD templates, ArgoCD configurations, and more.
These components are automatically assembled into a production-ready service with a single click from the developer. This self-service experience is made possible through our self-service platform, which abstracts the complexity and handles everything end-to-end — from provisioning the Git repository to wiring CI/CD pipelines and deploying to Kubernetes.
We’ll dive into how this automation works in the next blog post.
But the impact is already clear: previously, spinning up a Kubernetes service involved about a week of coordinated effort across multiple teams—from infrastructure provisioning to CI/CD, security, and deployment alignment.
For developers, this end-to-end process could take up to a few sprints, depending on priorities and resource availability.
Today, it takes just five seconds.
During hackathons or workshops, we routinely create dozens of fully functioning services and their corresponding Git repositories — all in a single click. This shift from weeks to seconds exemplifies the power of platform engineering done right.
Summary.
At Via, we built a self-service platform that lets developers easily provision infrastructure and deploy services using standardized, secure defaults, accelerating development and reducing operational overhead.
Huge thanks to Alex Berenshtein, Senior Platform Engineer, who led the implementation of the self-service platform, and Omer Shacham, Via’s Lead Architect, for shaping its design and guiding us toward this milestone.
This is the first post in our self-service blog series — stay tuned for the next one, where we’ll share deeper implementation details and highlight additional challenges we tackled while scaling and evolving the platform.
We’re hiring!
Want to work on an engineering team where you can build domain knowledge of transit in close collaboration with transit planners to build solutions that otherwise would not be possible to imagine? Join us.



.png?width=71&height=47&name=Sioux%20Falls%20Webinar%20(6).png)
